인덱스 튜닝의 두 가지 핵심요소
- 인덱스는 큰 테이블에서 소량 데이터를 검색할 때 사용한다.
- 온라인 트랜젝션 처리 (OLPT) 시스템에서는 소량 데이터를 주로 검색하므로 인덱스 튜닝이 무엇보다 중요하다.
- 첫번째. 인덱스 스캔 효율화 튜닝
- 인덱스 스캔 과정에서 발생하는 비효율을 줄이는 것.
- 두번째. 랜덤 엑세스 퇴소화 튜닝
- 테이블 액세스 횟수를 줄이는 것.
- 인덱스 스캔 후 테이블 레코드를 엑세스할 때 랜덤 I/O 방식을 사용함.
- 데이터 베이스 성능이 느린 이유는 디스크 I/O 때문이다. 읽어야 할 데이터량이 많고, 그 과정에 디스크 I/O가 많이 발생할 때 느리다.
- 인덱스를 많이 사용하는 OLTP 시스템이라면 디스크 I/O 중에서도 랜덤 I/O가 특히 중요하다.
- 이 두개중 성능에 미치는 영향이 더 큰 것은 **‘랜덤 액세스 최소화 튜닝'**이다. 그래서 SQL 튜닝은 랜덤 I/O와의 전쟁이라는 표현을 쓰기도 한다. ⇒ 3장에서 자세히 다룬다.
- 랜덤 액세스란?
- 데이터를 저장하는 블록을 한번에 여러 개 액세스 하는 것이 아니라 한 번에 하나의 블록만을 액세스 하는 방식이다.
한 번에 여러 개의 블록을 액세스 한다면 같은 양의 데이터에 대해 적은 횟수의 디스크 I/O가 발생하기 때문에 성능이 향상될 수 있다.
인덱스 구조
- 인덱스 없이 데이터를 검색하려면, 테이블을 처음부터 끝까지 모두 읽어야 한다.
- 반면, 인덱스를 이용하면 일부만 읽고 멈출 수 있다. ⇒ 즉, 범위 스캔이 가능하다.
- 범위스캔이 가능한 이유는 인덱스가 정렬되어있기 때문이다.
- DBMS는 일반적으로 B*Tree 인덱스를 사용한다.
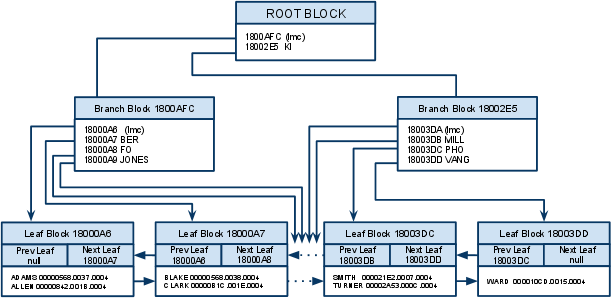
- 나무(Tree)를 거꾸로 뒤집은 모양이어서 뿌리(루트, Root)가 위쪽에 있고, 가지(브랜치, Branch)를 거쳐 맨 아래에 잎사귀(리프, Leaf)가 있다.
- 루트와 브랜치 블록에 있는 각 레코드는 하위 블록에 대한 주소값을 갖는다.
- 키값은 하위 블록에 저장된 키값의 범위를 나타낸다.
- 루트와 브랜치 블록에는 키값을 갖지 않는 특별한 레코드가 하나 있다. 이를 ‘LMC’라고 하며 ‘Leftmost Child’의 줄임말이다. LMC는 자식 노드 중 가장 왼쪽 끝에 위치한 블록을 가리킨다.
- 리프 블록에 저장된 각 레코드는 키값 순으로 정렬돼 있을 뿐만 아니라 테이블 레코드를 가리키는 주소값, 즉 ROWID를 갖는다. 인덱스 키값이 같으면 ROWID 순으로 정렬된다.
- 인덱스를 스캔하는 이유는, 검색 조건을 만족하는 소량의 데이터를 빨리 찾고 거기서 ROWID를 얻기 위해서다.
- ROWID는 아래와 같이 데이터 블록(DBA, Data Block Address)와 로우 번호로 구성되므로 이 값을 알면 테이블 레코드를 찾아갈 수 있다.
- ROWID = 테이블 블록 주소 + 로우 번호
- 테이블 블록 주소 = 데이터 파일 번호 + 블록 번호
- 블록 번호 : 데이터파일 내에서 부여한 상대적 순번
- 로우 번호 : 블록 내 순번
인덱스 탐색 과정은 수직적 탐색과 수평적 탐색으로 나눌 수 있다.
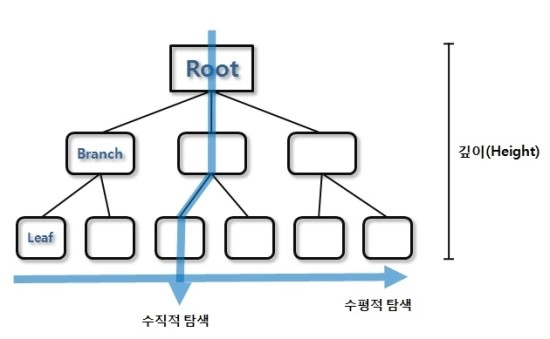
- 수직적 탐색 : 인덱스 스캔 시작지점을 찾는 과정
- 수평적 탐색 : 데이터를 찾는 과정
인덱스 수직적 탐색
- 정렬된 인덱스 레코드 중 조건에 만족하는 첫 번째 레코드를 찾는 과정이다. 즉, 인덱스 스캔 시작지점을 찾는 과정이다.
- 인덱스 수직점 탐색은 루트(Root) 블록에서부터 시작한다. 루트를 포함해 브랜치(Branch) 블록에 저장된 각 인덱스 레코드는 하위 블록에 대한 주소값을 갖는다. 루트에서 시작해 리프(Leaf) 블록까지 수직적 탐색이 가능한 이유다.
- 수직적 탐색은 ‘조건을 만족하는 레코드’를 찾는 과정이 아니라 ‘조건을 만족하는 첫 번째 레코드’를 찾는 과정임을 반드시 기억하자.
인덱스 수평적 탐색
- 수직적 탐색을 통해 스캔 시작점을 찾았으면, 찾고자 하는 데이터가 더 안 나타날 때까지 인덱스 리프 블록을 수평적으로 스캔한다.
- 인덱스 리프 블록끼리는 서로 앞뒤 블록에 대한 주소값을 갖는다. 즉, 양방향 연결 리스트(double linked list) 구조다. 좌에서 우로, 또는 우에서 좌로 수평적 탐색이 가능한 이유다.
- 인덱스를 수평적으로 탐색하는 이유는 첫째, 조건절에 만족하는 데이터를 모두 찾기 위해서고 둘째, ROWID를 얻기 위해서다. 필요한 컬럼을 인덱스가 모두 갖고 있어 인덱스만 스캔하고 끝나는 경우도 있지만, 일반적으로 인덱스를 스캔하고서 테이블도 액세스한다. 이 때 ROWID가 필요하다.
결합 인덱스 구조와 탐색
- DBMS가 사용하는 B*Tree 인덱스는 엑셀처럼 평면 구조가 아니다. 다단계 구조다.
- 두 개 이상 컬럼을 결합해서 인덱스를 만들 수도 있다. 고객 테이블에 성별과 고객명 기준으로 만든 인덱스 구조에서 인덱스를 [고객명 + 성별]로 구성하든, [성별 + 고객명]으로 구성하든 읽는 인덱스 블록 개수가 똑같다는 사실이다.
- 하지만 DBMS가 사용하는 B*Tree 인덱스는 엑셀처럼 평면 구조가 아니다. 루트에서 브랜치를 거쳐 리프 블록까지 탐색하면서 ‘여자'이면서 ‘유관순'인 첫 번째 사원을 바로 찾아간다. 거기서부터 두 건을 스캔한다. 정확히 말하면, 유관순이 아닌 레코드를 만날 때까지 세 건을 스캔한다.
- 인덱스를 어떻게 구성하든 블록 I/O 개수가 같으므로 성능도 똑같다. ⇒ ?
- B*Tree의 B는 balanced다. 어떤 값으로 탐색하더라도 인덱스 루트에서 리프 블록에 도달하기까지 읽는 블로 수가 같음을 의미한다. 즉, 루트로부터 모든 리프 블록까지의 높이는 항상 같다.
반응형
'Book & Lecture Review > 친절한 SQL 튜닝' 카테고리의 다른 글
| 인덱스 확장 기능 사용법 (2) | 2022.05.11 |
|---|---|
| 인덱스 기본 사용법 (0) | 2022.05.11 |
| SQL 데이터 저장 구조 및 I/O 메커니즘 (4) | 2022.05.04 |
| 소프트 파싱 vs 하드 파싱 (1) | 2022.05.04 |
| SQL 파싱과 최적화 (3) | 2022.05.04 |



